
Java集合进阶
2025.03.16
集合进阶
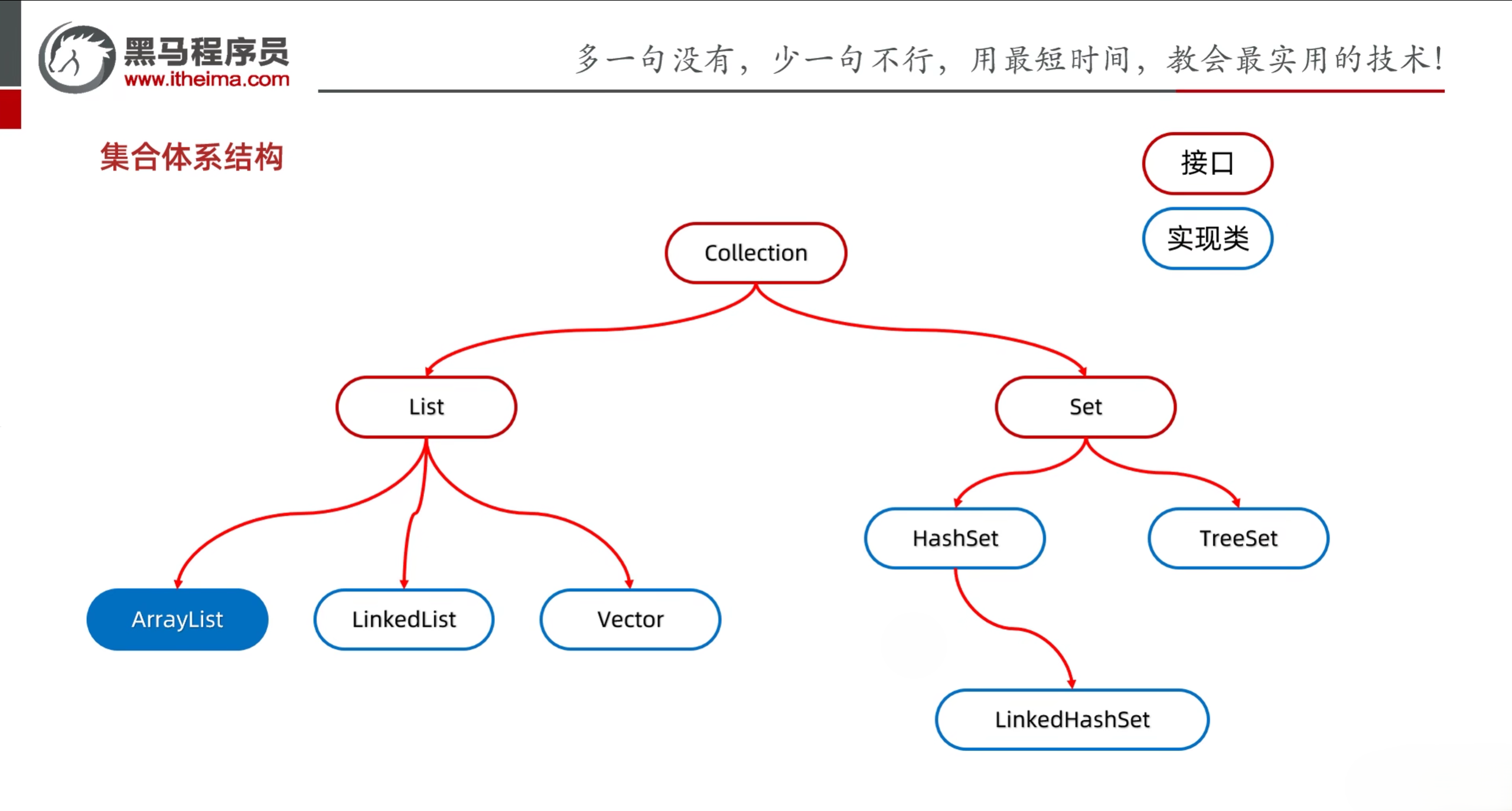
集合有很多种,可以大致分为两大类:Collection和Map
- Collection:单列集合,添加数据时每次添加一个元素
- List:添加的元素是有序(存和取的顺序一致)、可重复、有索引
- ArrayList
- LinkedList
- Vector
- Set:添加的元素是无序、不重复、无索引
- HashSet
- LinkedHashSet
- TreeSet
- HashSet
- List:添加的元素是有序(存和取的顺序一致)、可重复、有索引
- Map:双列集合,添加数据时每次添加一对数据
一、Collection
- Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的
- Collection是一个接口,我们不能直接创建它的对象,只能创建它实现类的对象
1.1 Collection常用方法
1.1.1 add(E e): 把给定的对象添加到当前集合中
- public boolean add(E e): 把给定的对象添加到当前集合中
- 如果往List系列集合中添加数据,那么返回值永远为true,因为List系列允许元素重复
- 如果往Set系列集合中添加数据,那么如果要添加的元素不存在,则返回值为true,如果要添加的元素已存在,则返回false
示例:
1 | import java.util.ArrayList; |
1.1.2 clear(): 清空集合中的所有元素
- public void clear(): 清空集合中的所有元素
示例:
1 | import java.util.ArrayList; |
1.1.3 remove(E e): 把给定的对象在当前集合中删除
- public boolean remove(E e): 把给定的对象在当前集合中删除
- 因为Collection定义的是共性的方法,所以不能通过索引进行删除,只能通过元素的对象进行删除
- 删除成功返回true,删除失败返回false
示例:
1 | import java.util.ArrayList; |
1.1.4 contains(Object obj): 判断当前集合中是否包含给定的对象
- public boolean contains(Object obj): 判断当前集合中是否包含给定的对象
- 底层是依赖equals方法进行判断是否存在的
- 如果集合中存储的是自定义对象,也想通过contains方法来判断是否包含,那么在javabean类中必须重写equals方法
示例:
1 | import java.util.ArrayList; |
1.1.5 isEmpty(): 判断当前集合是否为空
- public boolean isEmpty(): 判断当前集合是否为空
示例:
1 | import java.util.ArrayList; |
1.1.6 size(): 返回集合中元素的个数/集合的长度
- public int size(): 返回集合中元素的个数/集合的长度
示例:
1 | import java.util.ArrayList; |
1.2 Collection遍历方式
Collection实现的是通用的遍历方式,由于Set中没有索引,所以不能使用索引进行遍历
Collection实现的遍历方式一共有三种:
- 迭代器遍历
- 增强for遍历
- Lambda表达式遍历
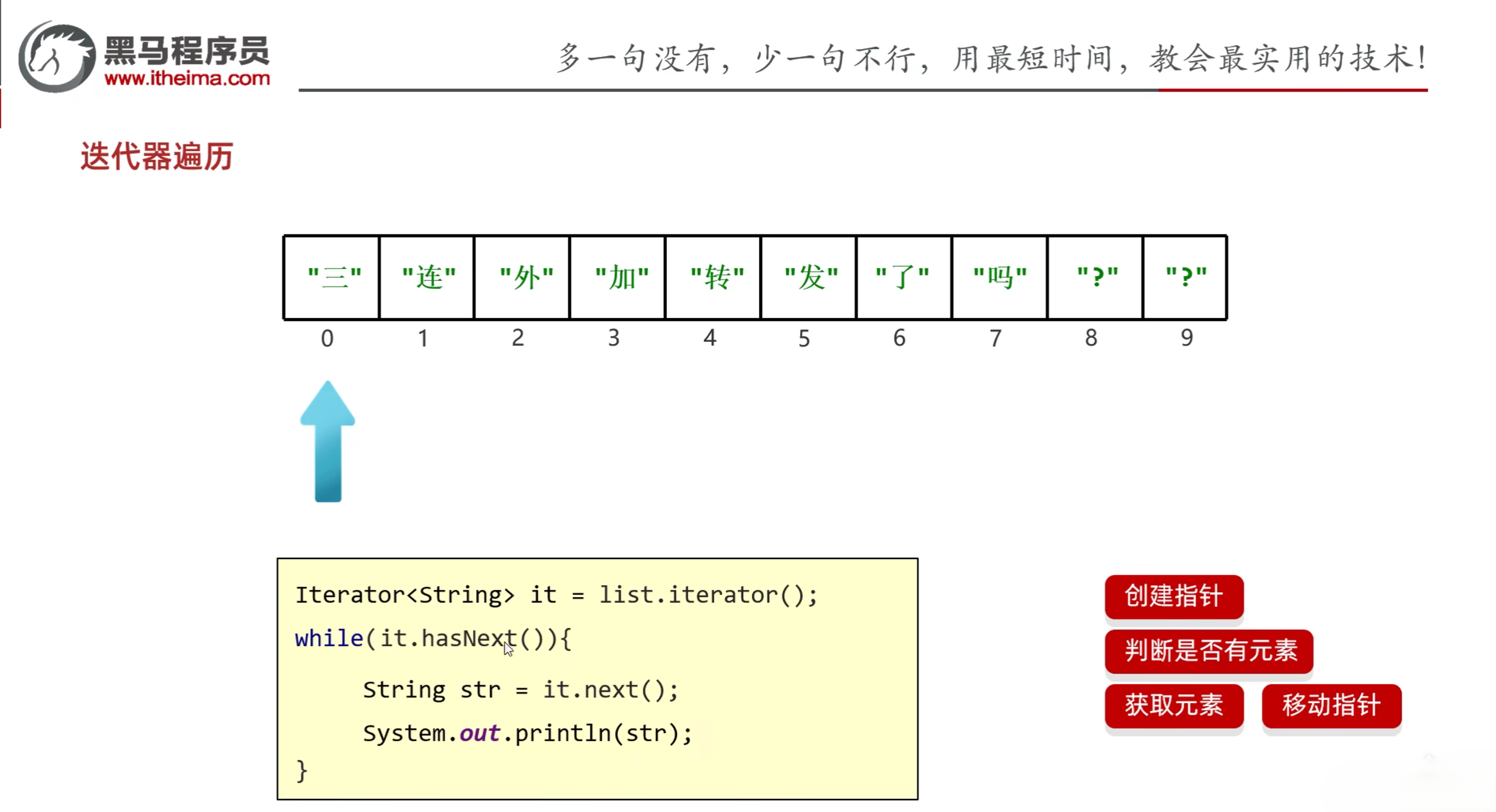
1.2.1 Iterator迭代器遍历
- 迭代器遍历不依赖于索引
- 迭代器在Java中的类是Iterator,迭代器是集合专用的遍历方式
- Collection集合获取迭代器:Iterator<E> iterator:返回迭代器对象,默认指向当前集合的0索引
- Iterator中的常用方法:
- boolean hasNext():判断当前位置是否有元素,有元素返回true,没有元素返回false
- E next():获取当前位置的元素,并将迭代器对象移向下一个位置
- remove():删除元素
示例:
1 | import java.util.ArrayList; |
细节注意点:
- 报错NoSuchElementException
- 迭代器遍历完毕,指针不会复位,如果要再次遍历需要使用新的迭代器对象
- 循环中只能使用一次next方法,一次循环中调用两次next会导致移动两次指针,有可能会导致越界
- 迭代器遍历,不能用集合的方法进行增加或删除,只能使用迭代器中的remove方法进行删除
1.2.2 增强for遍历
- 增强for的底层就是迭代器,为了简化迭代器的代码书写的
- 它是JDK5之后出现的,其内部原理就是一个Iterator迭代器
- 所有的单列集合和数组才能用增强for进行遍历
- 格式:for (元素的数据类型 变量名:数组或集合){}
- 例:for (String s:list){System.out.println(s);}
- 注意点:
- s其实就是一个第三方变量,在循环过程中依次表示集合中的每一个数据
- 快速生成方式:集合名字.for 回车
- 修改s不会改变集合中原本的数据
示例:
1 | import java.util.ArrayList; |
1.2.3 Lambda表达式遍历
- default void forEach(Consumer<? super T> action):结合lambda遍历集合
示例:
1 | import java.util.ArrayList; |
2025.03.17
二、List
List集合的特点:
- 有序:存和取的元素顺序一致
- 有索引:可以通过索引操作元素
- 可重复:存储的元素可以重复
2.1 List常用方法
List集合的特有方法:
- Collection的方法List都继承了
- List集合因为有索引,所以多了很多索引操作的方法
2.1.1 add(int index,E element):在此集合中的指定位置插入指定的元素
- void add(int index,E element): 在此集合中的指定位置插入指定的元素
示例:
1 | import java.util.ArrayList; |
2.1.2 remove(int index):删除指定索引处的元素,返回被删除的元素
- E remove(int index): 删除指定索引处的元素,返回被删除的元素
- List中有两种remove
- 一种是删除指定元素
- 一种是删除指定索引处的元素
- 在调用方法时,如果方法出现了重载现象,优先调用实参跟形参一致的那个方法
示例:
1 | import java.util.ArrayList; |
2.1.3 set(int index,E element):修改指定索引处的元素,返回被修改的元素
- E set(int index,E element): 修改指定索引处的元素,返回被修改的元素
示例:
1 | import java.util.ArrayList; |
2.1.4 get(int index):返回指定索引处的元素
- E get(int index): 返回指定索引处的元素
示例:
1 | import java.util.ArrayList; |
2.2 List遍历方式
List遍历方式一共有五种,其中三种是继承于Collection的:
- 迭代器遍历: 在遍历过程中需要删除元素,使用迭代器遍历
- 列表迭代器遍历:在遍历过程中需要添加元素,使用列表迭代器遍历
- 增强for遍历:仅仅想遍历,使用增强for或Lambda表达式遍历
- Lambda表达式遍历:仅仅想遍历,使用增强for或Lambda表达式遍历
- 普通for循环:如果遍历的时候想操作索引,可以使用普通for
2.2.1 列表迭代器遍历
- 利用ListIterator进行遍历
- 可以在遍历过程中使用迭代器本身的add方法添加元素:iterator.add()
示例:
1 | import java.util.ArrayList; |
2.2.2 普通for遍历
- 利用for循环和get方法遍历
示例:
1 | import java.util.ArrayList; |
2025.03.18
三、数据结构
数据结构是计算机底层存储、组织数据的方式,是指数据相互之间是以什么样的方式排列在一起的
常见的数据结构:
- 栈
- 队列
- 数组
- 链表
- 二叉树
- 二叉查找树
- 平衡二叉树
- 红黑树
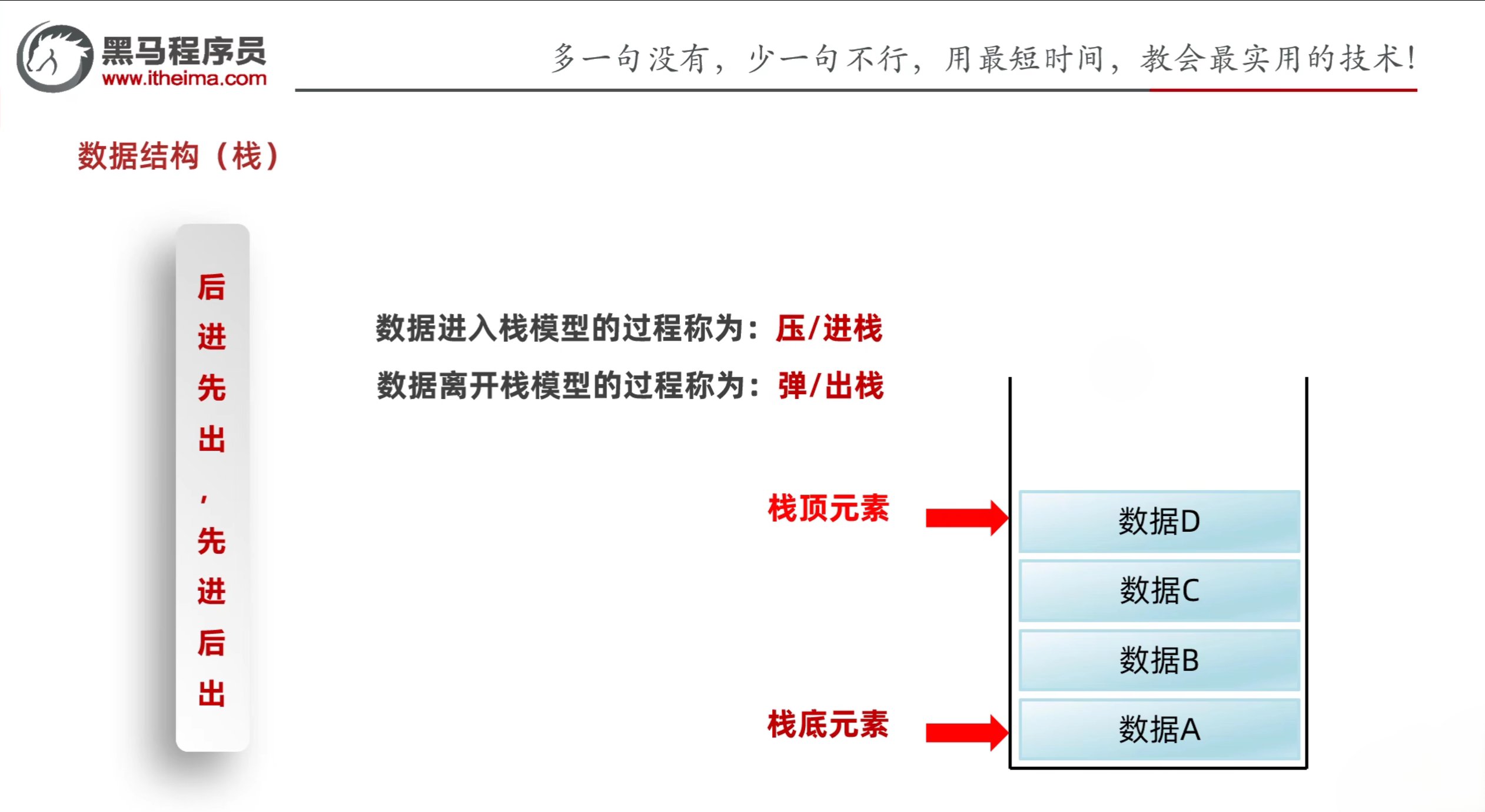
3.1 栈
- 栈的特点:后进先出,先进后出
- 数据进入栈的过程:压/进栈
- 数据离开栈的过程:弹/出栈
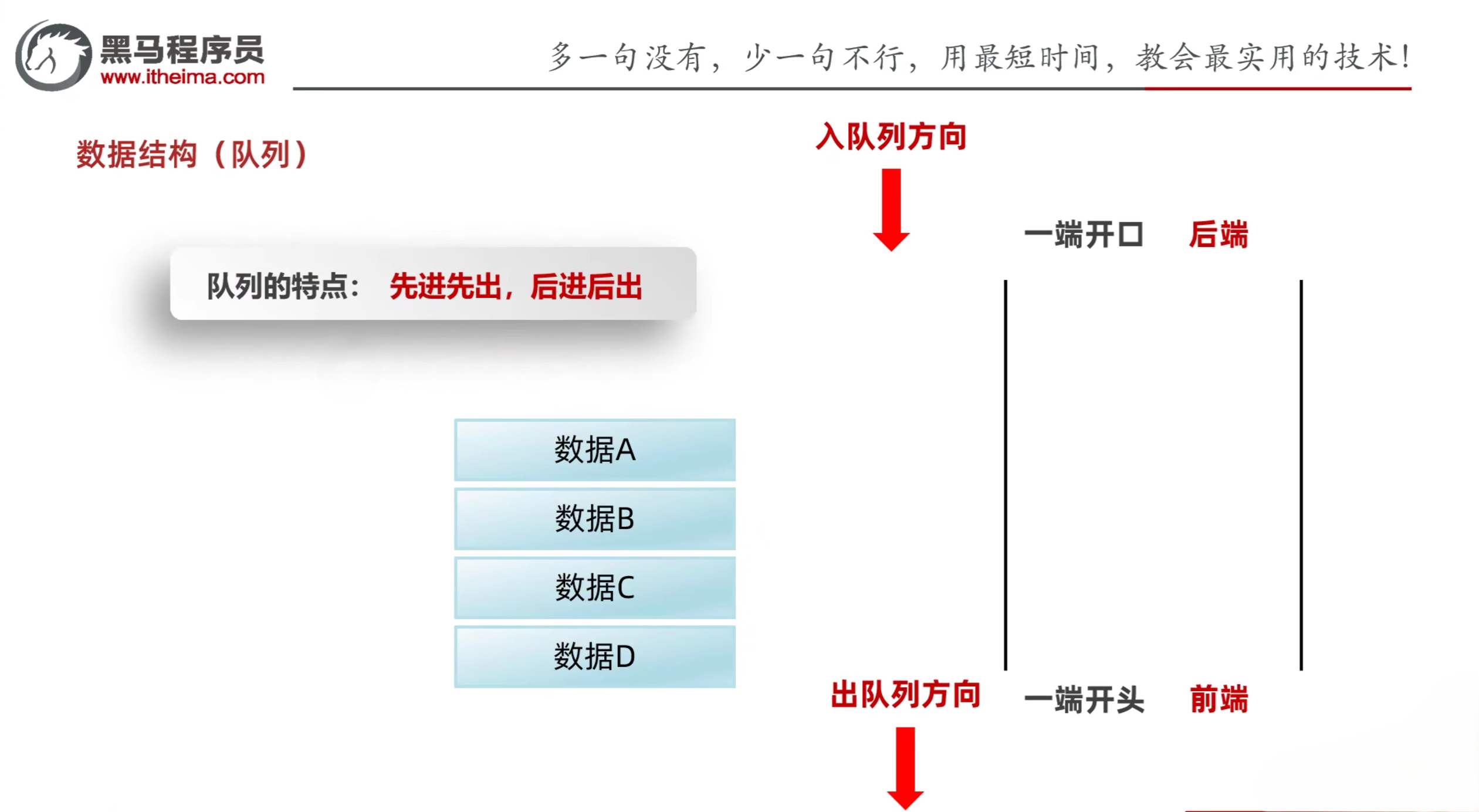
3.2 队列
- 队列的特点:先进先出,后进后出
- 数据从后端进入队列的过程:入队列
- 数据从前端离开队列的过程:出队列
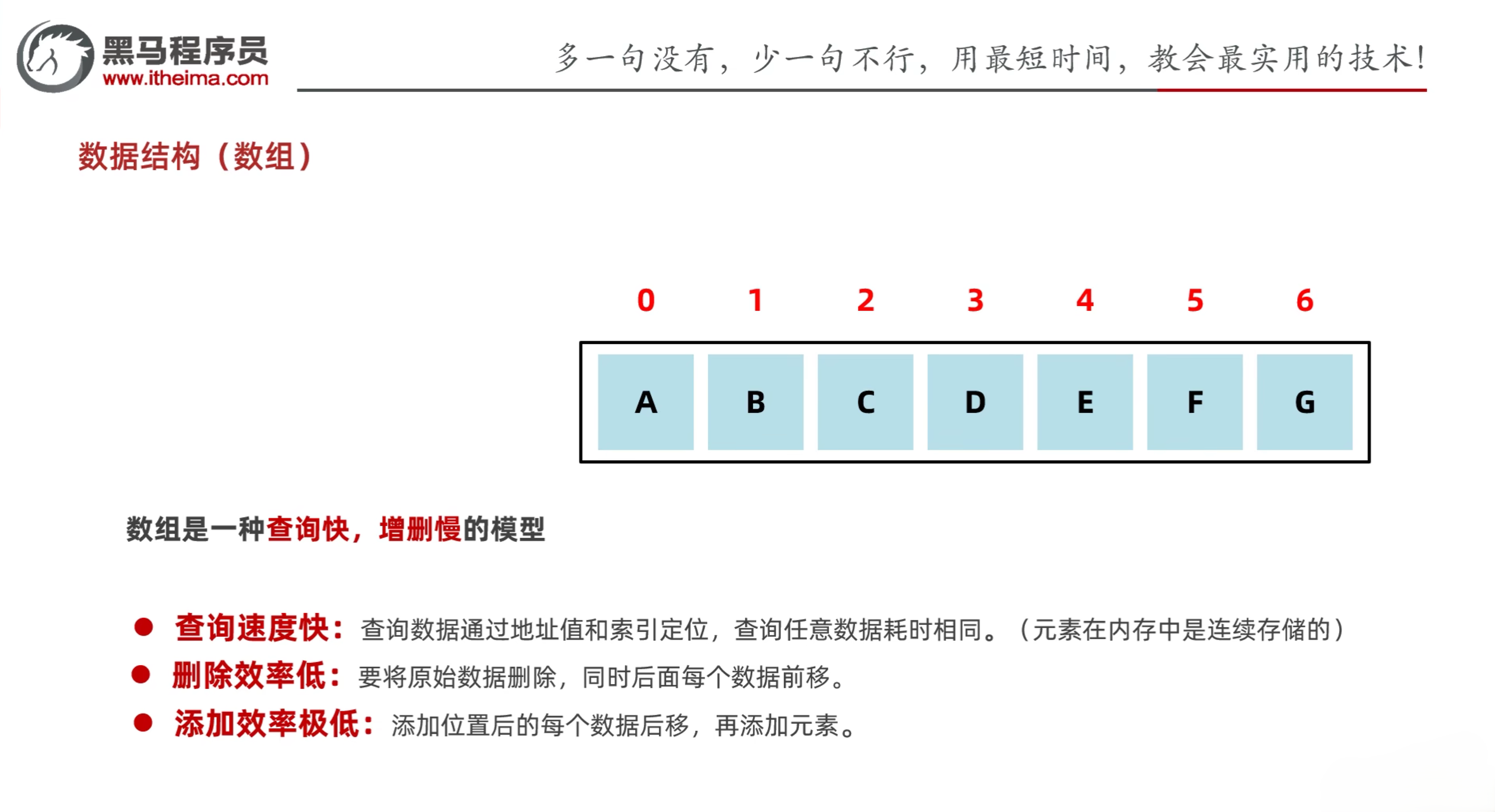
3.3 数组
- 数组是一种查询快,增删慢的模型
- 查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同(元素在内存中是连续存储的)
- 删除效率低:要将原始数据删除,同时后面每个数据前移
- 添加效率极低:添加位置后的每个数据都要后移再添加元素
3.4 链表
- 链表中的单位是结点,其中存储具体的数据以及下一个结点的地址值
- 链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址
- 链表查询慢,无论查询哪个数据都要从头开始找
- 链表增删快



2025.03.21
3.5 ArrayList集合底层原理
- 利用空参创建的集合,在底层创建一个默认长度为0的数组
- 添加第一个元素时,底层会创建一个新的长度为10的数组
- 存满时,会扩容1.5倍(创建一个新数组并将原数组中的元素全部拷贝到新数组中)
- 如果一次添加多个元素,1.5倍放不下,则新创建数组的长度以实际为准
- ArrayList的size不仅表示其大小,还表示添加下个元素时的位置
创建ArrayList并第一次向里面添加数据时的原理:
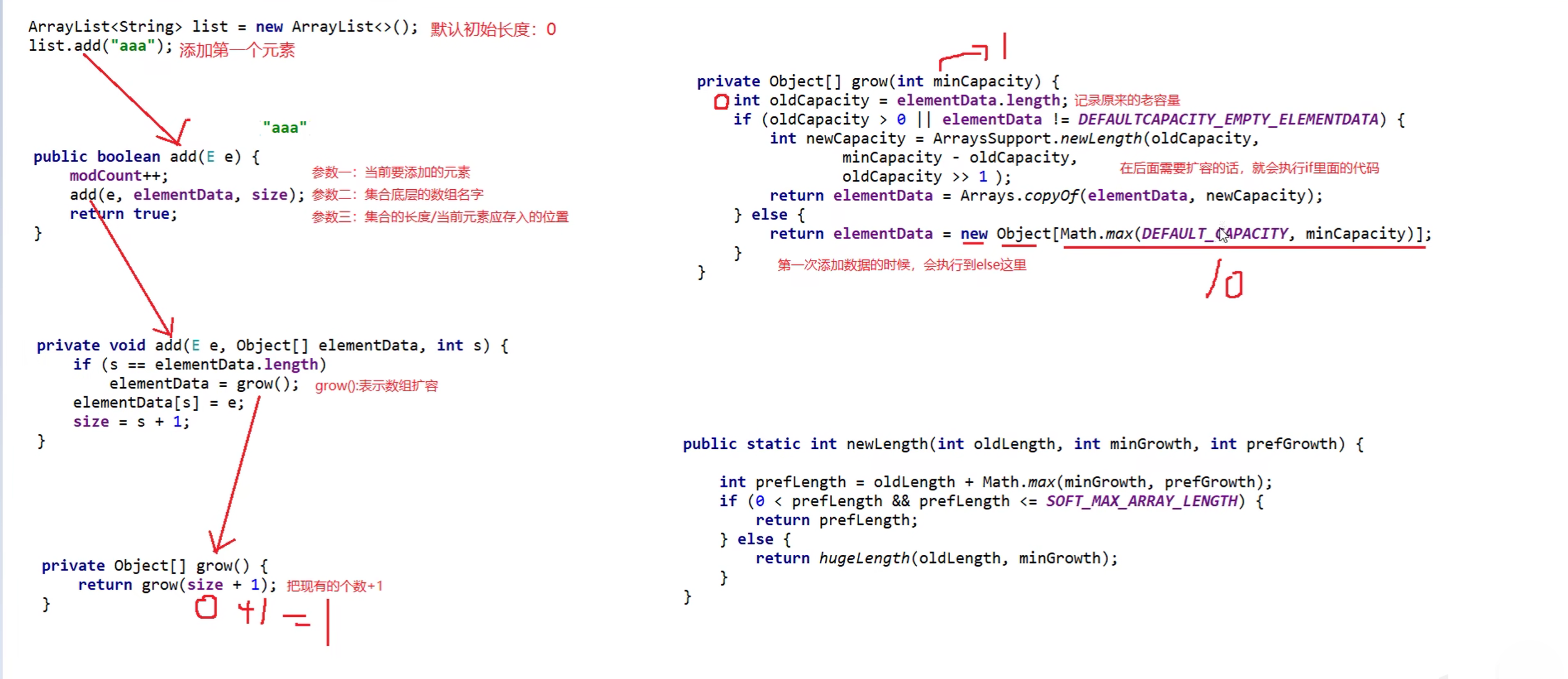
当ArrayList已满需要扩容时的原理:

3.6 LinkedList集合、迭代器底层原理
- LinkedList底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的(首尾相连)
- 有很多首尾操作的特有API
- public void addFirst(E e): 在该列表开头插入指定的元素
- public void addLast(E e): 在该列表末尾插入指定的元素
- public E getFirst(): 返回此列表中的第一个元素
- public E getLast(): 返回此列表中的最后一个元素
- public E removeFirst(): 从此列表中删除并返回第一个元素
- public E removeLast(): 从此列表中删除并返回最后一个元素
- 迭代器对象的三个参数
- cursor: 当前指向的元素
- lastRet: 当前元素的上一个元素
- expectedModCount: 表示集合变化的次数,每add或remove一次,这个变量就会自增
创建LinkedList并向里面添加数据时的原理:

创建迭代器时的底层原理:

2025.03.24
3.7 树
-
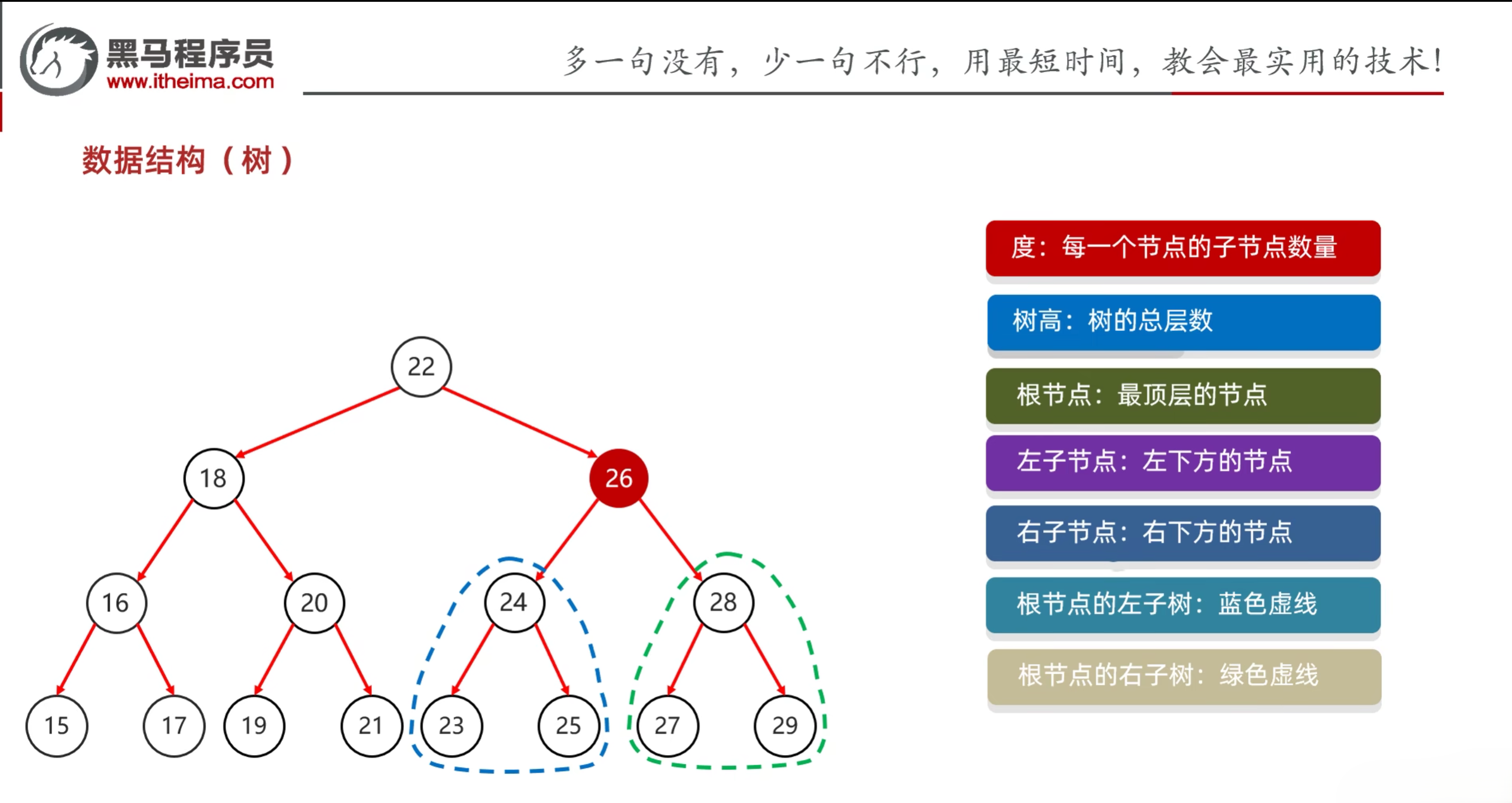
树的结构:
-
树的每个节点包含四个值:
- 父节点地址
- 值
- 左子节点地址
- 右子节点地址
-
度:每一个节点的子结点数量
-
树高:树的总层数
-
根节点:最顶层的节点
-
左子结点:左下方的节点
-
右子节点:右下方的节点
3.7.1 二叉查找树
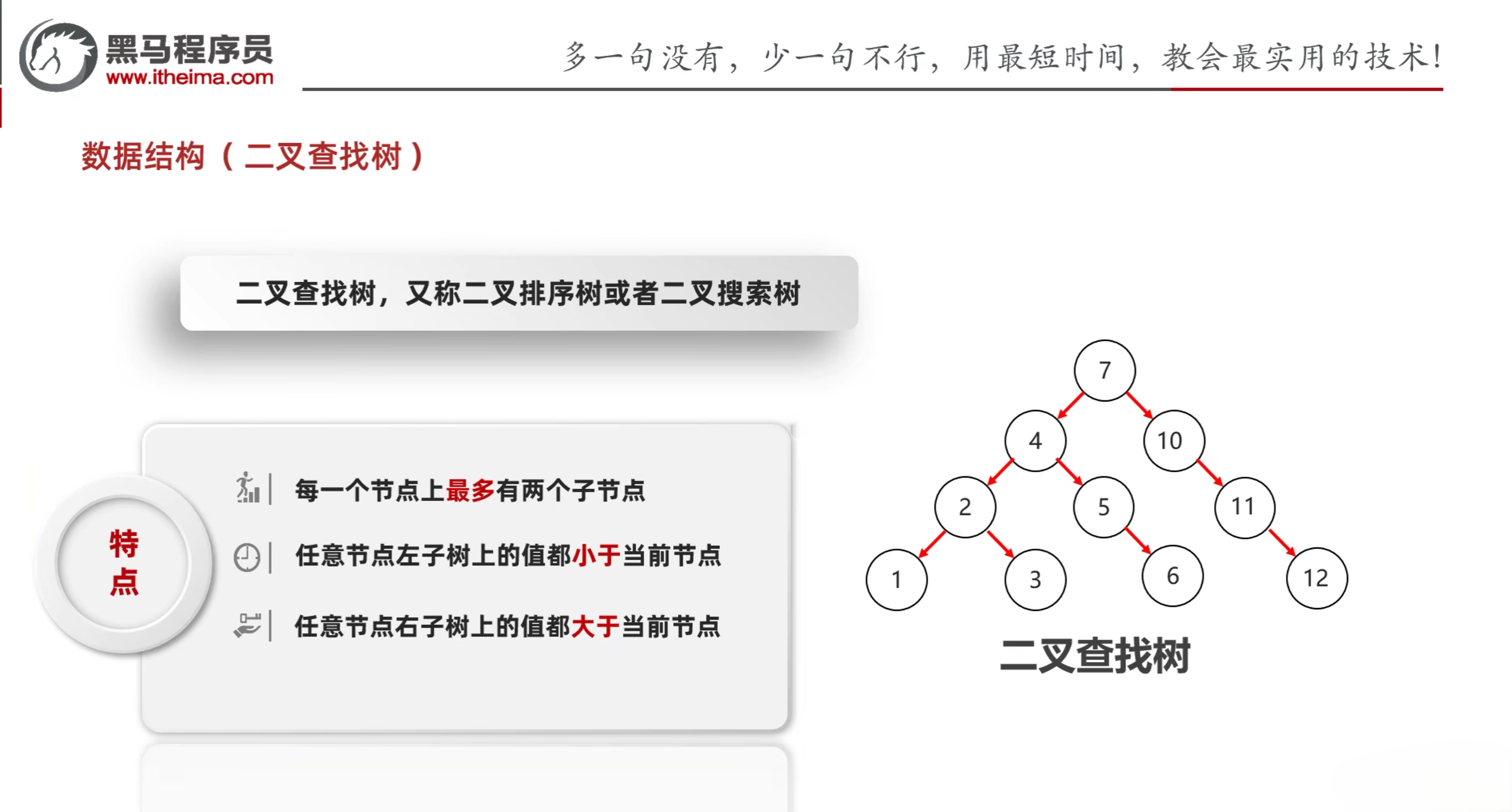
- 二叉查找树,又称二叉排序树或者二叉搜索树
- 特点:
- 每一个节点上最多有两个子结点
- 任意节点左子树上的值都小于当前节点
- 任意节点右子树上的值都大于当前节点
- 二叉查找树添加节点规则:
- 小的存左边
- 大的存右边
- 一样的不存
3.7.2 二叉树遍历方式
- 前序遍历:根->左->右
- 中序遍历:左->根->右
- 后序遍历:左->右->根
- 层序遍历:一层一层遍历
3.7.3 平衡二叉树
- 由于二叉查找树可能会因数据分布造成两边不平衡的问题,所以才有平衡二叉树
- 规则:任意节点左右子树高度差不超过1
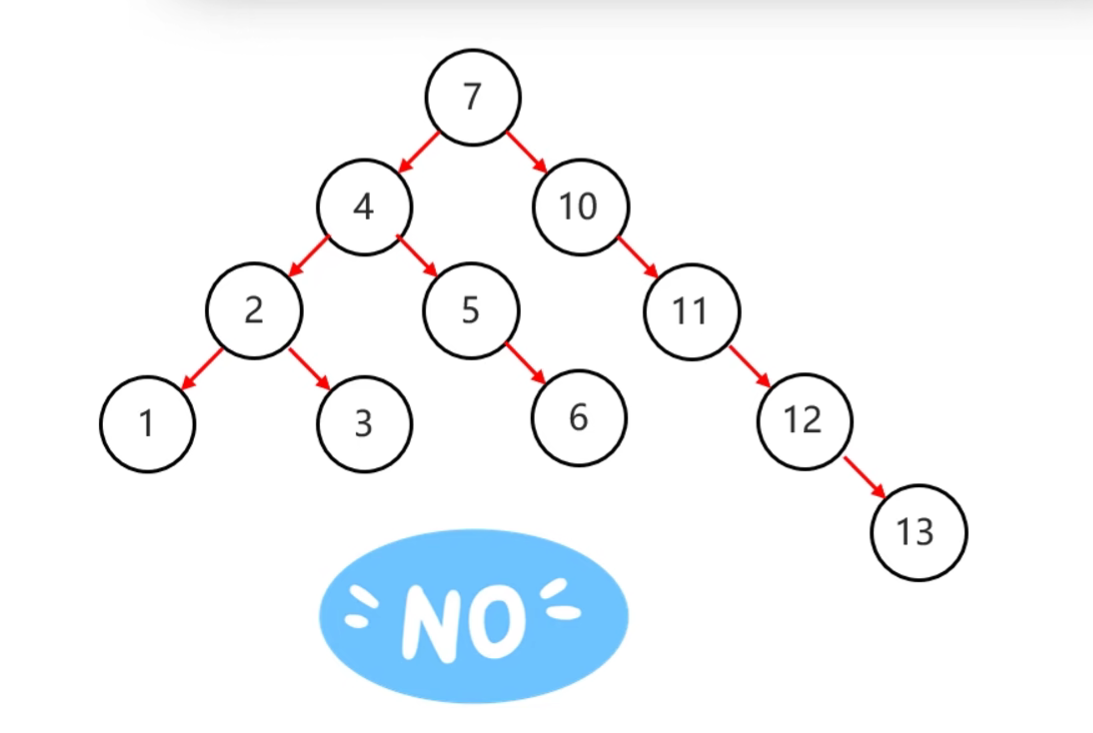 |
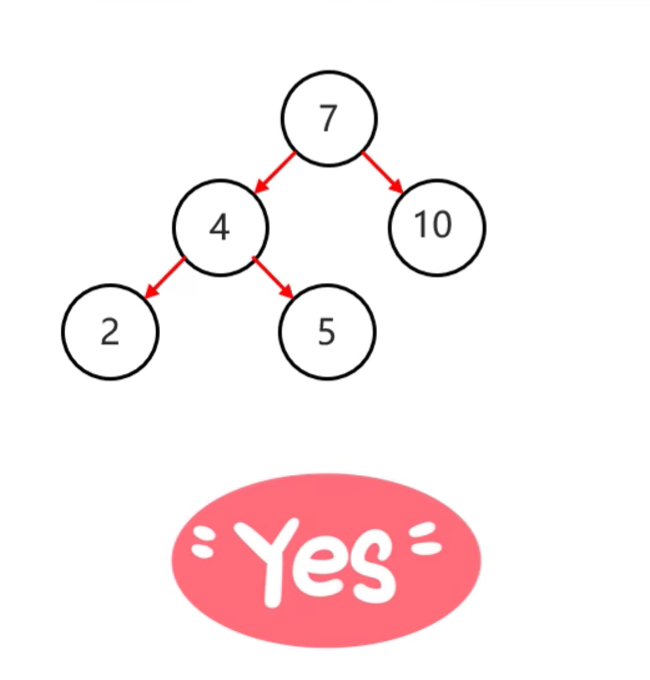 |
|---|
- 平衡二叉树的旋转机制:由于平衡二叉树要保持平衡,所以在添加节点时需要使用旋转机制
- 左旋步骤:
- 确定支点:从添加的节点开始,不断地往父节点找不平衡的节点
- 将根节点的右侧往左拉
- 原先的右子节点变成新的父节点,并把多余的左子结点出让,给已降级的根节点当右子节点
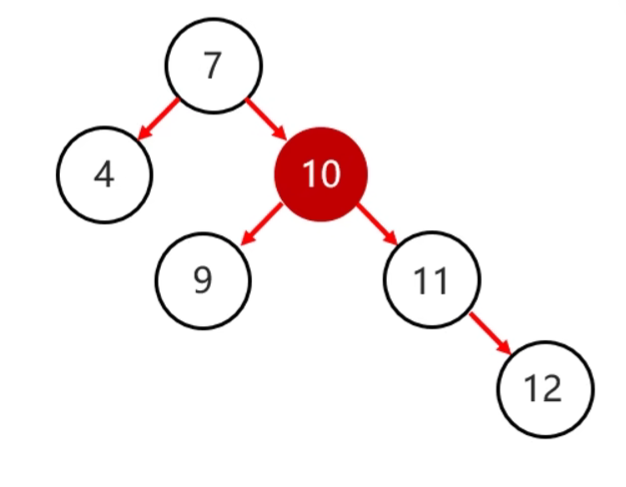 |
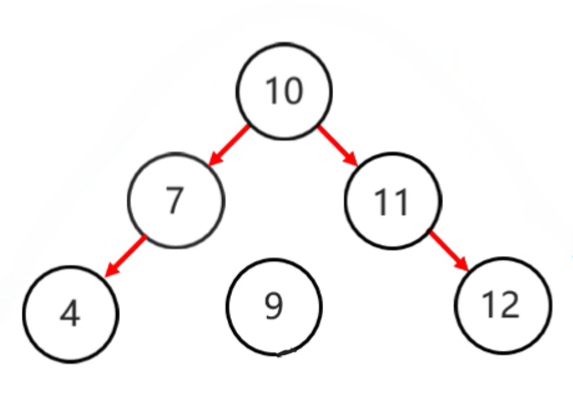 |
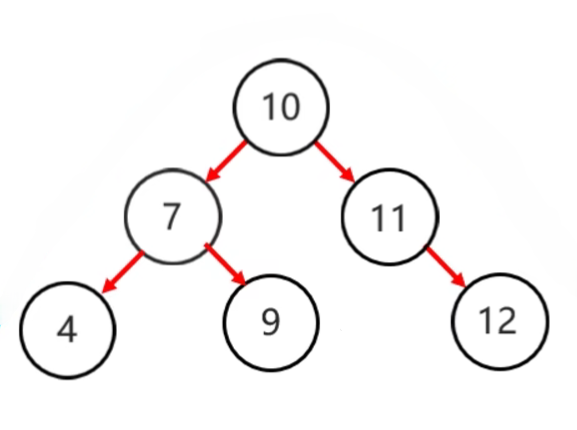 |
|---|
- 右旋步骤:
- 确定支点:从添加的节点开始,不断地往父节点找不平衡的节点
- 将根节点的左侧往右拉
- 原先的左子节点变成新的父节点,并把多余的右子结点出让,给已降级的根节点当左子节点
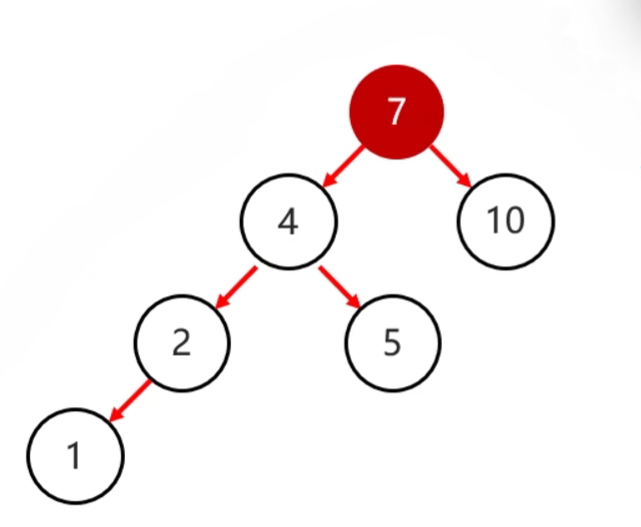 |
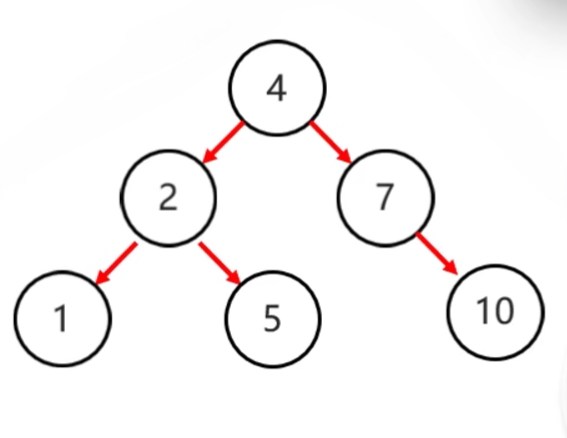 |
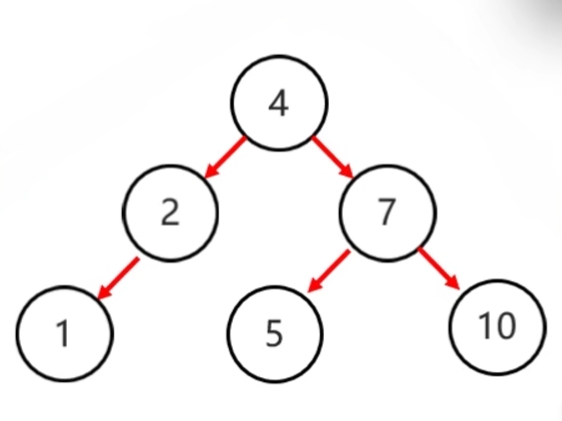 |
|---|
- 平衡二叉树需要旋转的四种情况
- 左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡
- 一次右旋
- 左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡
- 先局部左旋,再整体右旋
- 右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡
- 一次左旋
- 右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡
- 先局部右旋,再整体左旋
- 左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡
3.7.4 红黑树
- 红黑树是一种自平衡的二叉查找树
- 1972年出现,当时被称为平衡二叉B树,后来1978年被修改为红黑树
- 它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色
- 每一个节点可以是红或者黑,红黑树不是高度平衡的,它的平衡是通过“红黑规则”进行实现的
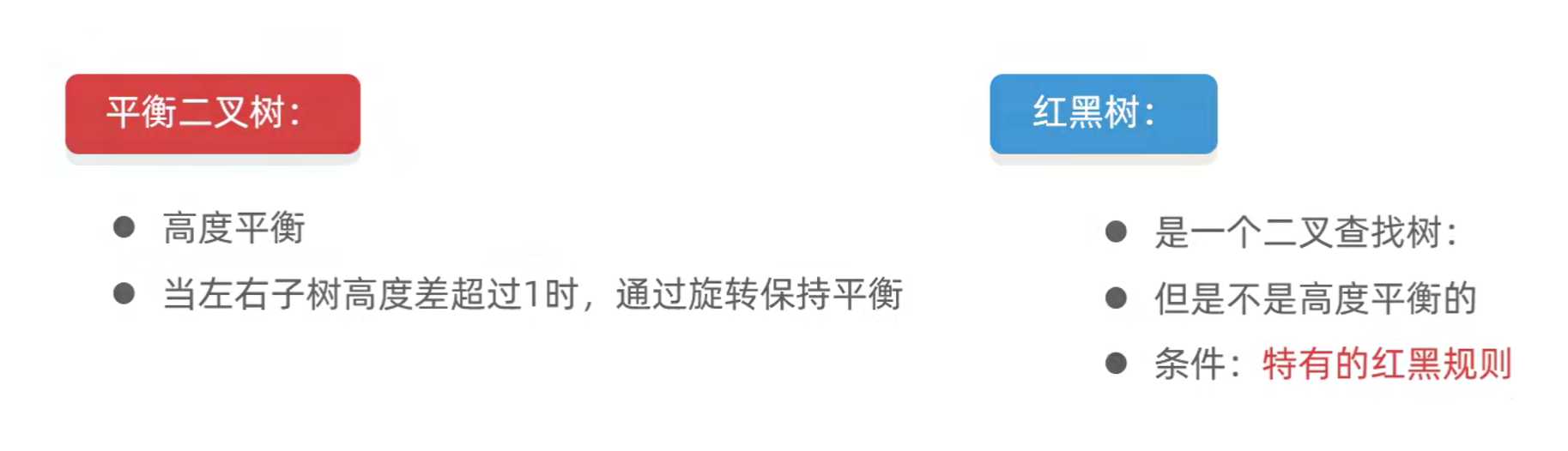
- 红黑树规则:
- 每一个节点或是红色的,或是黑色的
- 根节点必须是黑色
- 如果一个节点没有子结点或者父节点,则该节点相应的指针属性为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
- 如果某一个节点是红色的,那么它的子结点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
- “左根右,根叶黑,不红红,黑路同”
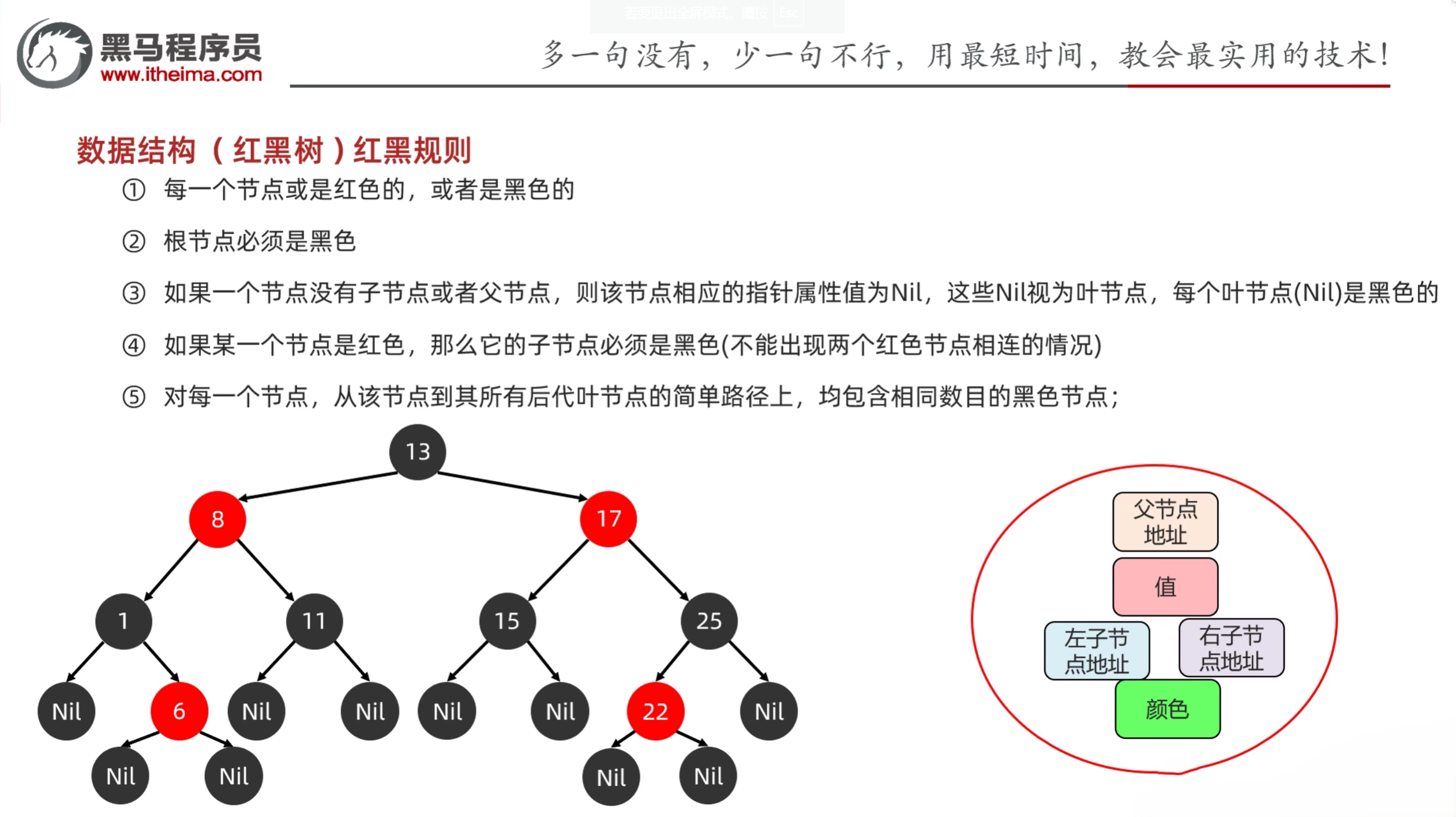
- 红黑树添加节点规则:
2025.03.23
四、泛型
- 泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查
- 泛型的格式:<数据类型>
- 泛型只能支持引用数据类型,如果想存储int这种基本数据类型,就需要使用它们的包装类Integer
- 如果集合不指定类型,默认所有数据类型均为Object类型,这会使我们在获取数据时无法使用该数据的特有行为(方法)
- 泛型的好处:
- 统一数据类型
- 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来
- Java中的泛型是伪泛型,在转换为字节码文件时数据还是Object类型,只不过在输出时又会强转为泛型
- 泛型的细节:
- 泛型中不能写基本数据类型
- 指定泛型的具体类型后,传递数据时,可传入该类型或者其子类类型
- 如果不写泛型,类型默认是Object
- 泛型可以在很多地方定义:
- 类后面:泛型类
- 方法上面:泛型方法
- 接口上面:泛型接口
4.1 泛型类
- 当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
- 格式:
修饰符 class 类名<类型>{
}
//举例:
public class ArrayList<E>{
}
- 此处的E可以理解为变量,但不是用来记录数据的,而是记录数据的类型,可以写成T、E、K、V等
示例:
1 | /* |
泛型类的使用:
1 | public class Main { |
4.2 泛型方法
- 方法中形参类型不确定时:
- 可以用类名后面定义的泛型<E>(本类中所有方法都能使用)
- 可以在方法声明上定义自己的泛型(只有本方法可以使用)
- 格式:
修饰符 <类型> 返回值类型 方法名(类型 变量名){
}
//举例:
public <T> void show(T t){
}
- 此处的T可以理解为变量,但不是用来记录数据的,而是记录类型的,可以写成T、E、K、V等
示例:
1 | //工具类ListUtil |
泛型方法的使用:
1 | import java.util.ArrayList; |
4.3 泛型接口
- 格式:
修饰符 interface 接口名<类型>{
}
//举例:
public interface List<E>{
}
- 泛型接口的使用:
- 实现类给出具体类型
- 实现类延续泛型,创建对象时再确定
示例:
1 | //实现方法一:实现类给出具体类型 |
4.4 泛型的继承和通配符
- 泛型不具备继承性,但是数据具备继承性
- 泛型里面写的是什么类型,那么只能传递什么类型的数据
示例:
1 | import java.util.ArrayList; |
- 使用泛型方法的弊端:它可以接受任意的数据类型
- 如果方法虽然不确定类型,但是希望对类型范围做一个约束,那么就可以使用泛型通配符
- 方式:
- ? extends E: 表示可以传递E或者E所有子类类型
- ? super E: 表示可以传递E或者E所有父类类型
示例:
1 | import java.util.ArrayList; |
2025.03.24
五、Set
Set系列集合:
- 无序:存取顺序不一致
- 不重复:可以去除重复
- 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素
Set集合的实现类:
- HashSet:无序、不重复、无索引
- LinkedSet:有序、不重复、无索引
- TreeSet:可排序、不重复、无索引
Set接口中的方法基本上与Collection的API一致
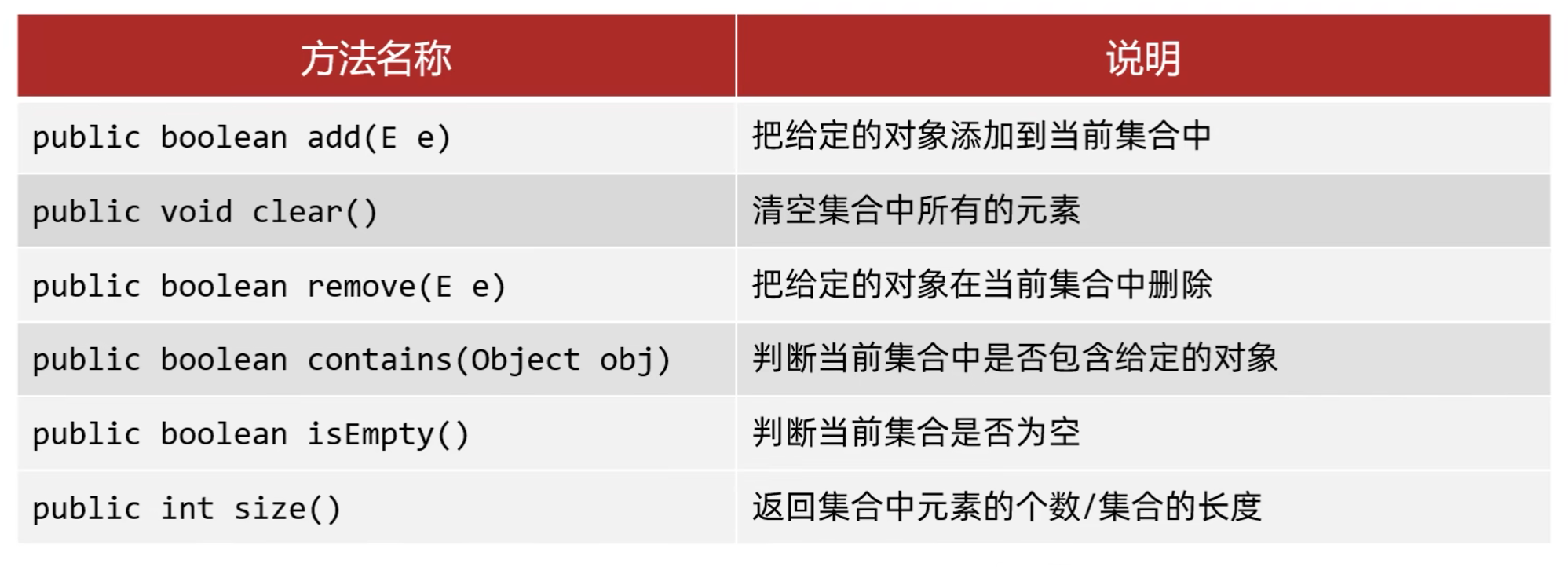
示例:
1 | import java.util.HashSet; |
5.1 HashSet
- HashSet底层原理:
- HashSet集合底层采取哈希表存储数据
- 哈希表是一种对于增删改查数据性能都比较好的结构
- 哈希表组成:
- JDK8之前:数组+链表
- JDK8之后:数组+链表+红黑树
- 哈希值:
- 根据hashCode方法计算出来的int类型的整数
- 该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
- 对象的哈希值特点:
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同属性值或不同地址值计算出来的哈希值也有可能一样(哈希碰撞)
示例:
1 | //Student类 |
1 | public class Main { |
5.2 HashSet底层原理
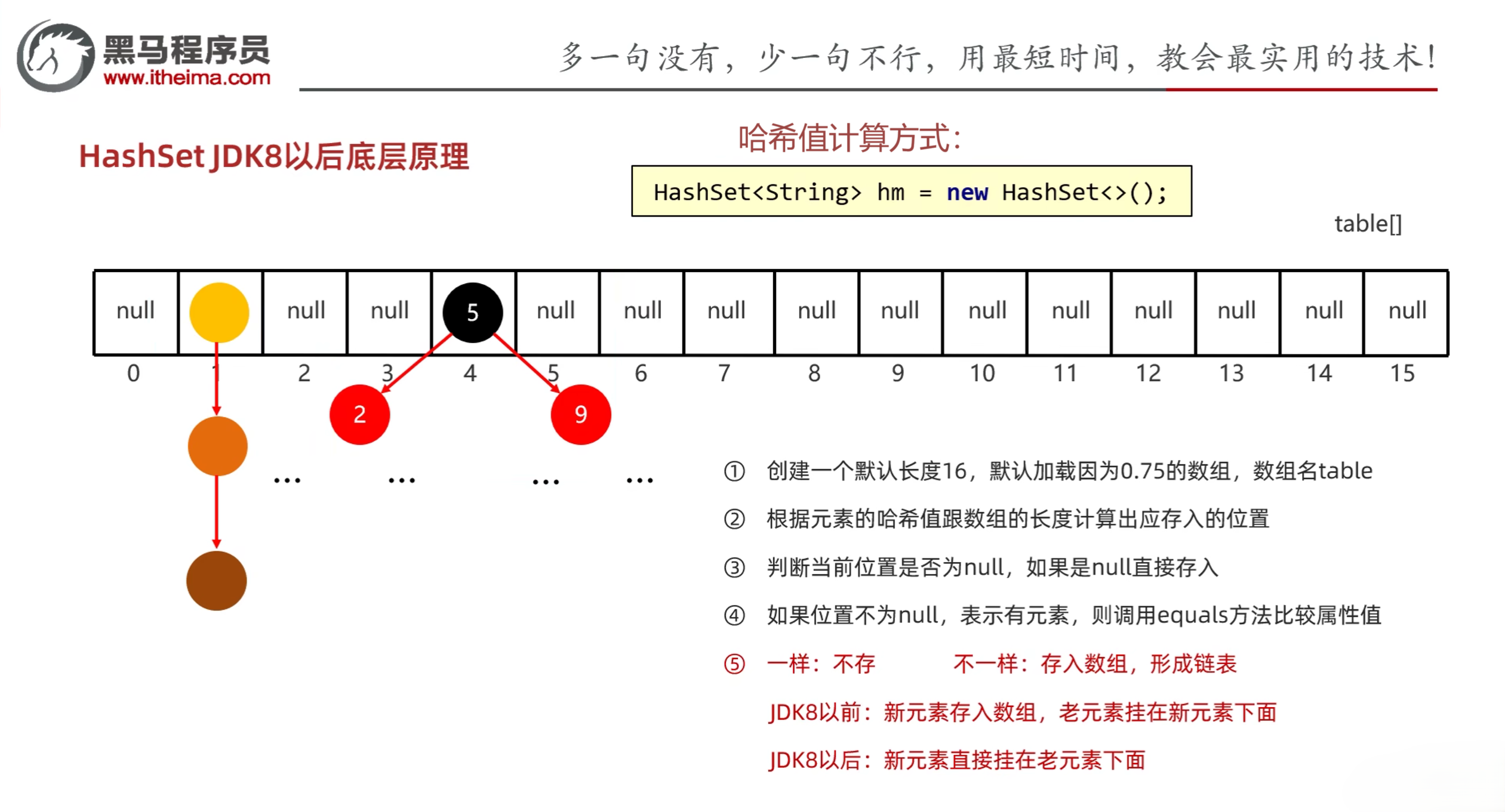
注意:
- JDK8以后,当链表长度超过8,而且数组长度大于等于64时,自动转换为红黑树
- 如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
5.3 LinkedHashSet
- 特点:有序、不重复、无索引
- 这里的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构依然是哈希表,只是每个元素又额外多了一个双链表机制存储顺序
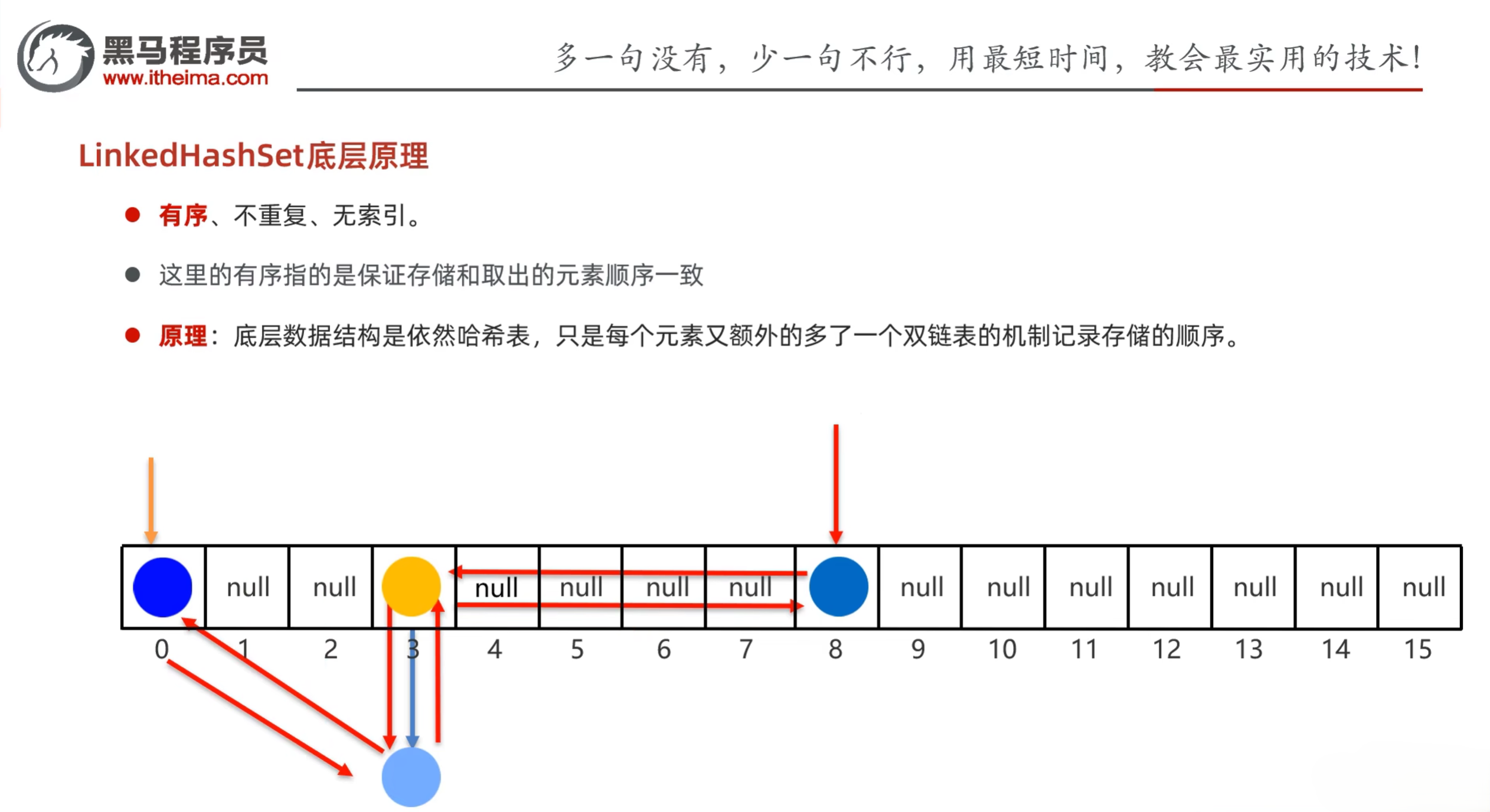
示例:
1 | import java.util.LinkedHashSet; |
2025.03.24
5.4 TreeSet
- TreeSet特点:
- 不重复、无索引、可排序
- 可排序:按照元素的默认规则(由小到大)排序
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都好
- TreeSet集合默认的规则:
- 对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
- 对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序
- TreeSet底层是红黑树,所以不需要重写hashCode和equals方法
- 使用TreeSet需要在类中使用Comparable接口并重写compareTo方法指定排序规则
示例:
1 | import java.util.TreeSet; |
5.5 TreeSet的两种比较方式
5.5.1 默认排序/自然排序
- 默认排序/自然排序:Javabean类实现Comparable接口指定比较规则
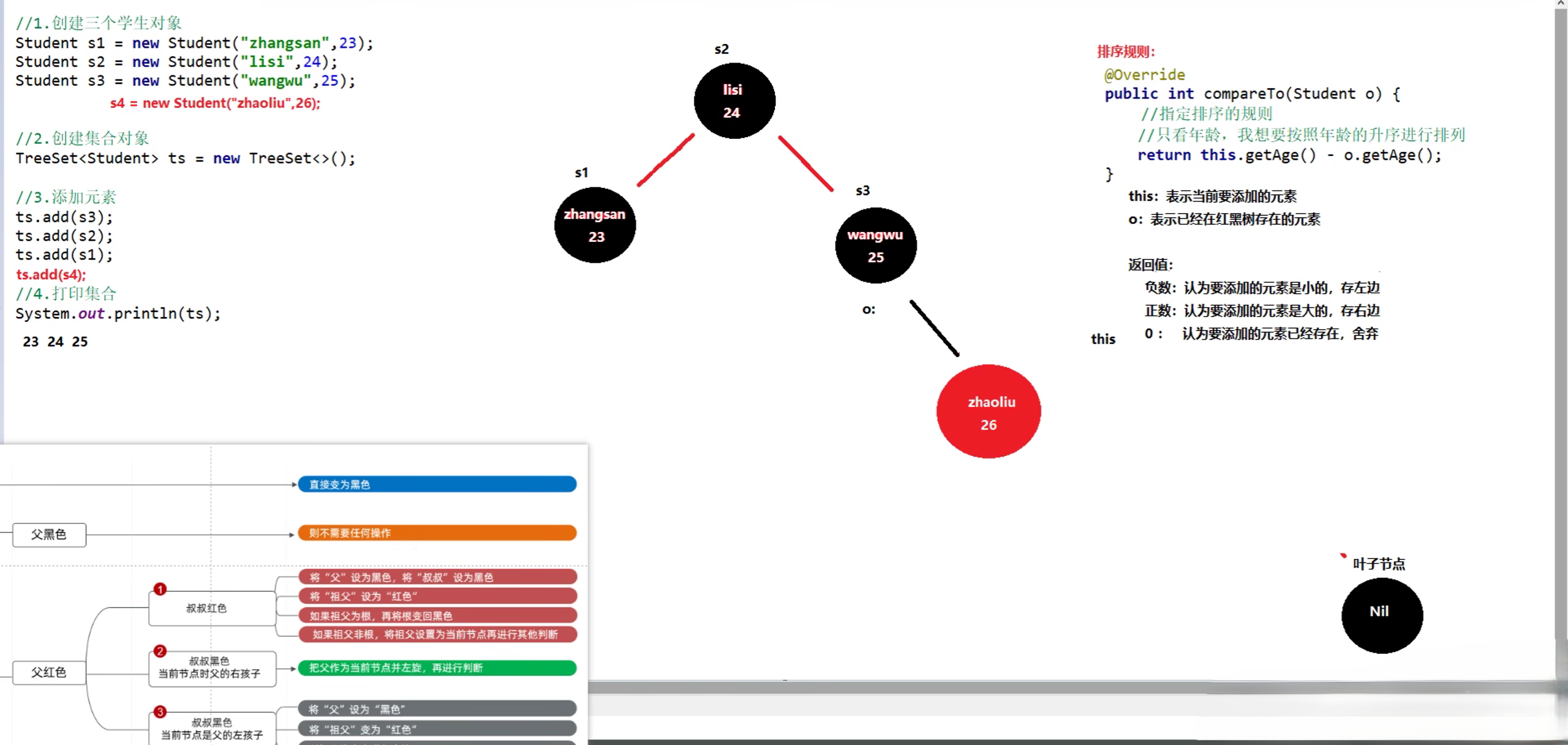
示例:
在Student类中实现按年龄大小排序
1 | public class Student implements Comparable<Student> { |
测试类:
1 | import java.util.TreeSet; |
5.5.2 比较器排序
- 比较器排序:创建TreeSet对象时,传递比较器Comparator指定规则
- 默认使用第一种,如果第一中不能满足要求再使用第二种
1 | import java.util.Comparator; |
总结
- 如果想要集合中的元素可重复:用ArrayList集合,基于数组的。
- 如果想要集合中的元素可重复,而且当前的增删操作明显多余查询:用LinkedList,基于链表的
- 如果想对集合中的元素去重:用HashSet集合,基于哈希表的
- 如果想对集合中的元素去重,而且保证存取顺序:用LinedHashSet集合,基于哈希表和双链表,效率低于HashSet
- 如果想对集合中的元素进行排序:用TreeSet集合,基于红黑树。后续也可以用List集合实现排序
2025.03.28
六、Map
- 单列集合每次添加一个元素
- 双列集合每次添加一对元素:分别为键和值
- 键:不能重复
- 值:可以重复
- 键和值一一对应,每一个键只能找到自己对应的值
- 键+值这个整体我们称之为键值对或键值对对象,在Java中叫做Entry对象
6.1 Map常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
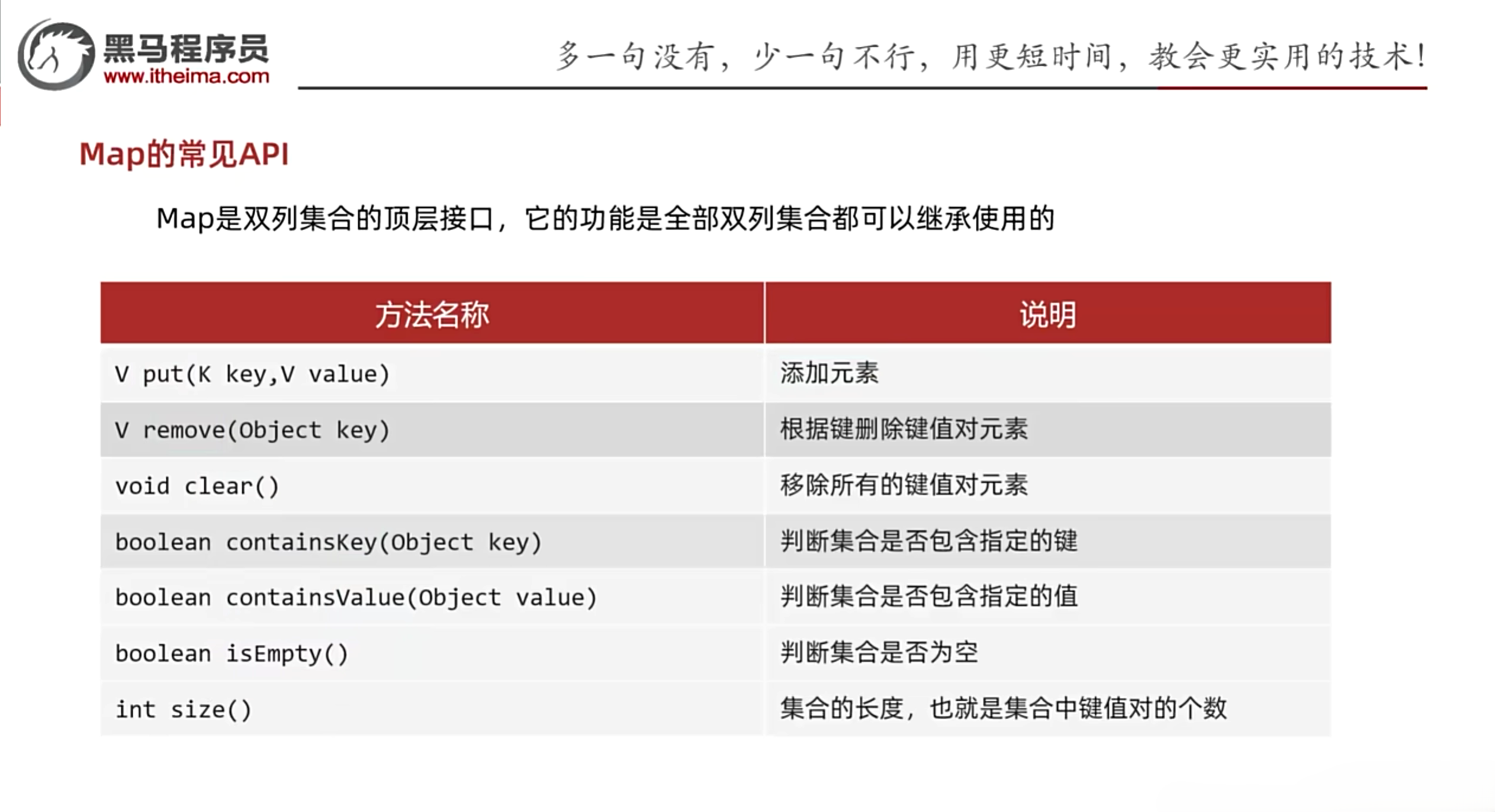
6.1.1 put():添加元素
- V put(K key,V value): 添加元素
- 再添加数据时,如果键不存在,那么直接把键值对对象添加到map集合中
- 如果键存在,那么会把原有的键值对对象覆盖,会把被覆盖的值进行返回
示例:
1 | import java.util.HashMap; |
6.1.2 remove():根据键删除键值对元素
- V remove(Object key): 根据键删除键值对元素
示例:
1 | import java.util.HashMap; |
6.1.3 clear():移除所有的键值对元素
- void clear():移除所有的键值对元素
示例:
1 | import java.util.HashMap; |
6.1.4 containsKey():判断集合是否包含指定的键
- boolean containsKey(Object key):判断集合是否包含指定的键
示例:
1 | import java.util.HashMap; |
6.1.5 containsValue():判断集合是否包含指定的值
- boolean containsValue(Object value):判断集合是否包含指定的值
示例:
1 | import java.util.HashMap; |
6.1.6 isEmpty():判断集合是否为空
- boolean isEmpty():判断集合是否为空
示例:
1 | import java.util.HashMap; |
6.1.7 size():集合的长度,也就是集合中键值对的个数
- int size():集合的长度,也就是集合中键值对的个数
示例:
1 | import java.util.HashMap; |
6.2 Map集合遍历方式
Map集合遍历方式一共有三种:
- 键找值
- 键值对
- Lambda表达式
6.2.1 键找值
- 先获取所有的键放到单列集合中,再使用get方法获取值
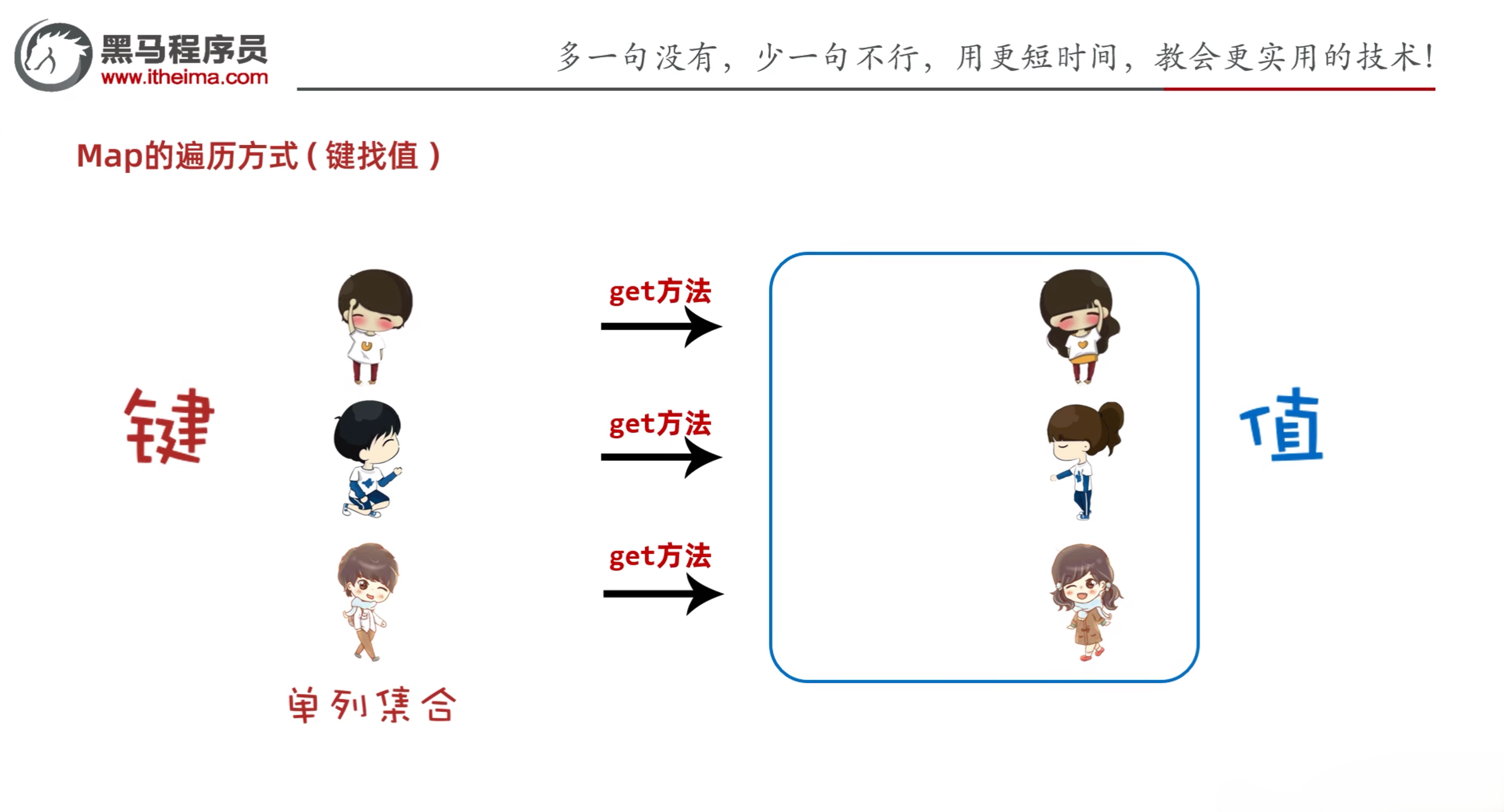
示例:
1 | import java.util.HashMap; |
6.2.2 键值对
- 先获取map中的每一对键值对对象,再使用getKay()和getValue()方法获取key和value

示例:
1 | import java.util.HashMap; |
6.2.3 Lambda表达式
- forEach()遍历
- 底层是使用增强for进行遍历的
示例:
1 | import java.util.HashMap; |
2025.03.29
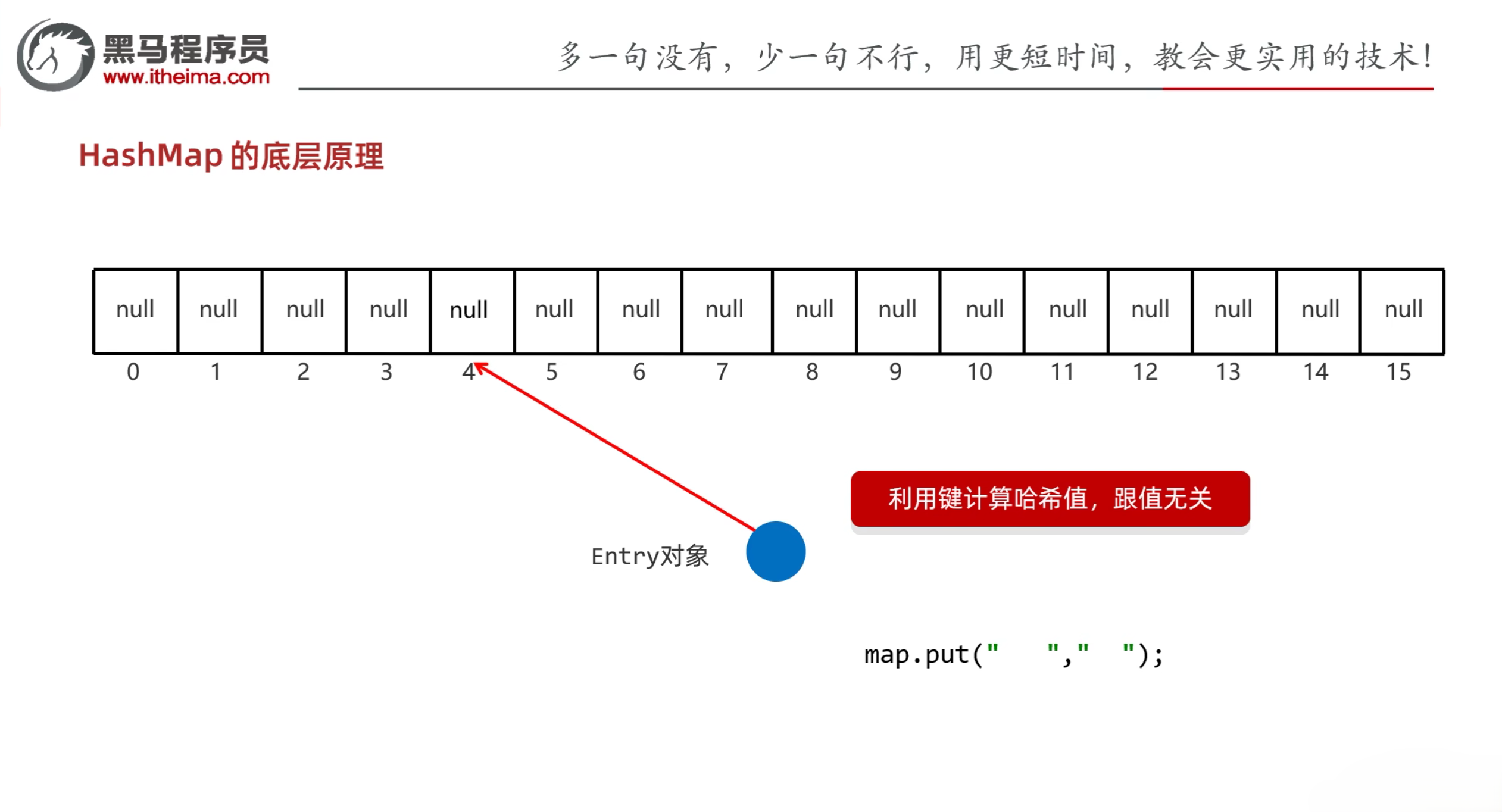
6.3 HashMap
- HashMap特点:
- HashMap是Map里面的一个实现类
- 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
- 特点都是由键决定的:无序、不重复、无索引
- HashMap跟HashSet底层原理是一模一样的,都是哈希表结构
6.4 HashMap练习
6.4.1 练习一
需求:创建一个HashMap集合,键是学生对象(Student),值是籍贯(String)
存储三个键值对元素并遍历
要求:同姓名,同年龄认为是一个学生
1 | //Student class |
1 | import java.util.HashMap; |
6.4.2 练习二
需求:某个班级80名学生,现在需要组成秋游活动,班长提供了四个景点依次是(A、B、C、D),每个学生只能选择一个景点,请统计出哪个景点想去的人最多
1 | import java.util.*; |
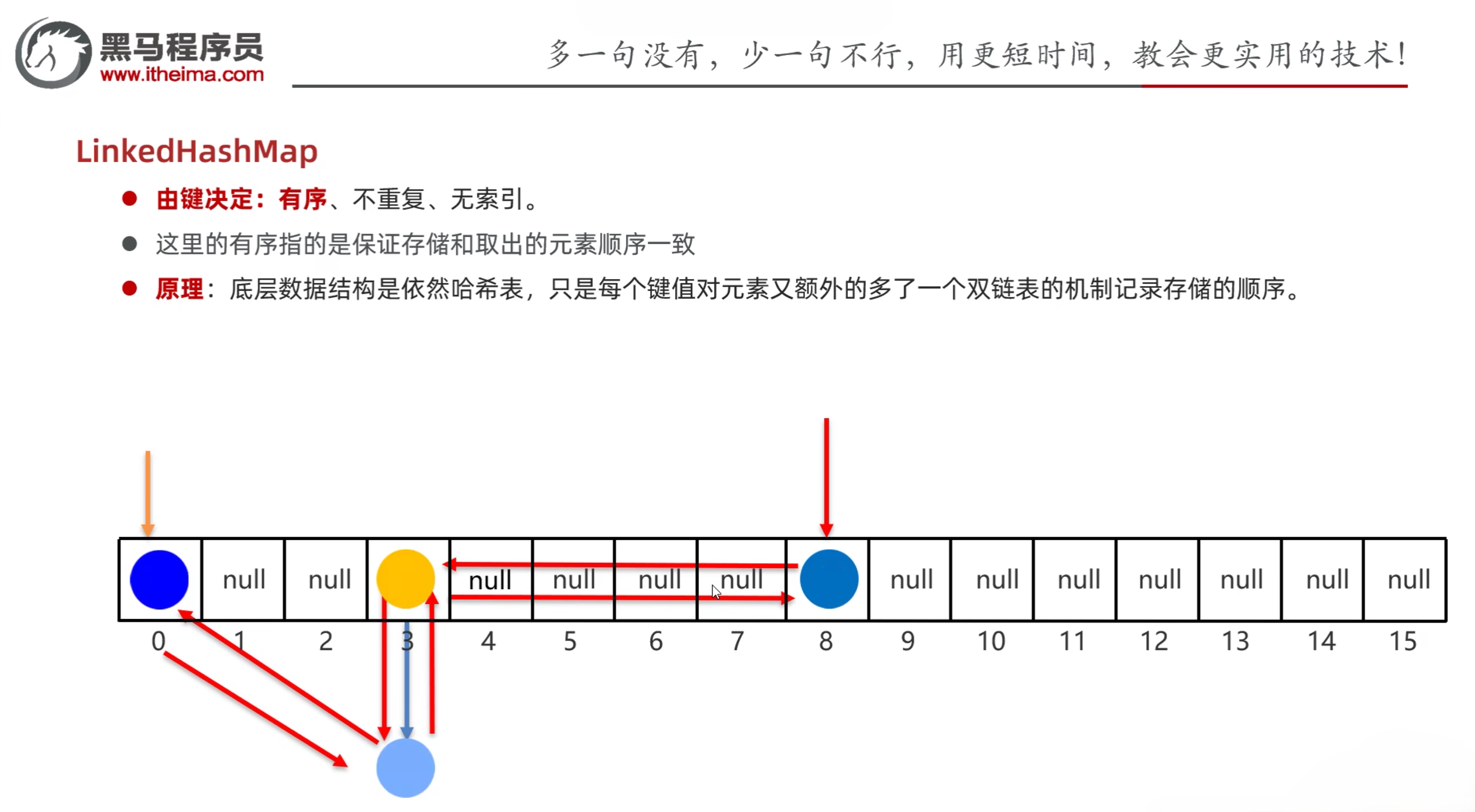
6.5 LinkedHashMap
- LinkedHashMap特点:
- 由键决定:有序、不重复、无索引
- 这里的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构依然是哈希表,只是每个键值对元素又额外多了一个双链表的机制记录存储的顺序
示例:
1 | import java.util.LinkedHashMap; |
6.6 TreeMap
- TreeMap特点:
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的
- 由键决定:不重复、无索引、可排序
- 可排序:对键进行排序
- 注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
- 键的排序规则
- 实现Comparable接口,指定比较规则
- 创建集合时传递Comparator比较器对象,指定比较规则
6.7 TreeMap的基本应用
6.7.1 需求1
需求:
键:整数表示id
值:字符串表示是商品名称
要求:按照id的升序排列,按照id的降序排列
1 | import java.util.Comparator; |
6.7.2 需求2
需求:
键:学生对象
值:籍贯
要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人
1 | //Student类-实现Comparable接口 |
1 | import java.util.TreeMap; |
6.7.3 需求3
需求:
字符串"aababcabcdabcde"
请统计字符串中每一个字出现的次数,并按照以下格式输出
输出结果:a(5)b(4)c(3)d(2)e(1)
1 | import java.util.*; |
2025.04.05
七、HashMap及TreeMap底层原理
7.1 HashMap源码分析
-
看源码之前需要了解的一些内容
1
2
3
4
5Node<K,V>[] table // 哈希表结构中数组的名字
DEFAULT_INITIAL_CAPACITY // 数组默认长度16
DEFAULT_LOAD_FACTOR // 默认加载因子0.75 -
HashMap里面每一个对象包含以下内容:
- 链表中的键值对对象,包含:
1
2
3
4int hash; //键的哈希值
final K key; //键
V value; //值
Node<K,V> next; //下一个节点的地址值- 红黑树中的键值对对象,包含:
1
2
3
4
5
6
7int hash; //键的哈希值
final K key; //键
V value; //值
TreeNode<K,V> parent; //父节点的地址值
TreeNode<K,V> left; //左子节点的地址值
TreeNode<K,V> right; //右子节点的地址值
boolean red; //节点的颜色 -
添加元素的时候至少考虑三种情况:
- 数组位置为null
- 数组位置不为null,键不重复,挂在下面形成链表或者红黑树
- 数组位置不为null,键重复,元素覆盖
源码分析:
1 | //参数一:键 |
7.2 TreeMap源码分析
-
TreeMap中每一个节点的内部属性
1
2
3
4
5
6K key; //键
V value; //值
Entry<K,V> left; //左子节点
Entry<K,V> right; //右子节点
Entry<K,V> parent; //父节点
boolean color; //节点的颜色 -
TreeMap类中中要知道的一些成员变量
1
2
3
4
5
6
7
8
9
10
11public class TreeMap<K,V>{
//比较器对象
private final Comparator<? super K> comparator;
//根节点
private transient Entry<K,V> root;
//集合的长度
private transient int size = 0;
} -
空参构造
1
2
3
4//空参构造就是没有传递比较器对象
public TreeMap() {
comparator = null;
} -
带参构造
1
2
3
4//带参构造就是传递了比较器对象。
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
} -
添加元素
1
2
3
4
5
6
7
8
9public V put(K key, V value) {
return put(key, value, true);
}
// 参数一:键
// 参数二:值
// 参数三:当键重复的时候,是否需要覆盖值
// true:覆盖
// false:不覆盖
源码分析:
1 | private V put(K key, V value, boolean replaceOld) { |
思考
-
TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
此时是不需要重写的。 -
HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?
不需要的。
因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的 -
TreeMap和HashMap谁的效率更高?
如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高
但是这种情况出现的几率非常的少。
一般而言,还是HashMap的效率要更高。 -
你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?
此时putIfAbsent本身不重要。
传递一个思想:
代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。
那么该逻辑一定会有B面。习惯:
boolean类型的变量控制,一般只有AB两面,因为boolean只有两个值
int类型的变量控制,一般至少有三面,因为int可以取多个值。 -
三种双列集合,以后如何选择?
HashMap LinkedHashMap TreeMap默认:HashMap(效率最高)
如果要保证存取有序:LinkedHashMap
如果要进行排序:TreeMap
2025.04.07
八、可变参数与Collections
8.1 可变参数
- 可变参数本质上就是一个数组
- 作用:在形参中接受多个数据
- 格式:数据类型…参数名称(如:int…a)
- 注意事项:
- 形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
示例:
1 | public class ArgsDemo { |
8.2 Collections
- java.util.Collections:是集合工具类
- 作用:Collections不是集合,而是集合的工具类
Collections常用API:
- public static <T> boolean addAll(Collection<T> c, T…elements): 批量添加元素
- public static void shuffle(List<?> list): 打乱list集合元素的顺序
- public static <T> void sort(List<T> list): 排序
- public static <T> void sort(List<T> list, Comparator<T> c): 根据指定规则排序
- public static <T> int binarySearch(List<T> list, T key): 以二分查找法查找元素
- public static <T> void copy(List<T> dest, List<T> src): 拷贝集合中的元素
- public static <T> int fill(List<T> list, T obj): 使用指定的元素填充集合
- public static <T> void max/min(Collection
coll): 根据默认的自然排序获取最大/小值 - public static <T> void swap(List<?> list, int i, int j): 交换集合中指定位置的元素
示例:
1 | public class CollectionsDemo2 { |
2025.04.08
九、不可变集合
- 创建不可变集合的应用场景
- 如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是个很好的实践
- 当集合对象被不可信的库调用时,不可变形式是安全的
- 简单来说就是不想让别人修改集合中的内容
- 创建不可变集合的书写格式
- 在List、Set、Map接口中都存在静态的of方法,可以获取一个不可变集合
- static <E> List<E> of(E…elements): 创建一个具有指定元素的List对象
- static <E> Set<E> of(E…elements): 创建一个具有指定元素的Set对象
- static <K, V> Map<K, V> of(E…elements): 创建一个具有指定元素的Map对象
- 这个集合不能添加,不能删除,不能修改,只能查询
- 注意:
- Set中元素不能重复
- Map中键不能重复
- Map中最多传递20个元素(10个键值对): 这是因为Key和Value都需要是可变参数,但是可变参数只能有一个
- 传递可变参数的不可变Map集合:
- static <K, V> Map<K, V> ofEntries(Entry<?> extends K, ? extends V>…entries)
示例:
1 | public class ImmutableDemo { |
1 | import java.util.HashMap; |
参考资料:
[1] 黑马程序员Java零基础视频教程_上部
[2] 黑马程序员Java零基础视频教程_下部










